Blog

How open data standards can help mitigate climate and disaster risk
Between 2009 and 2019, around two billion people were affected by disasters. As the climate emergency increases the frequency and intensity of these events, it’s more important than ever to have access to better data, so that governments and humanitarian organisations can effectively prevent, mitigate and manage the impact of them.
Open Data Services is new technology delivery partner of the International Aid Transparency Initiative
Open Data Services is the new technology delivery partner for the International Aid Transparency Initiative — a global data initiative to improve the transparency of development and humanitarian resources and their results to address poverty and crises.

Open Fibre Data Standard: opening up fibre optic broadband infrastructure
Fibre optic networks are essential infrastructure for a modern economy, but the telecom sector lacks readily available and usable data on these networks. We’ve been working on the Open Fibre Data Standard (OFDS), a new data standard that describes how to structure and publish data on fibre optic broadband infrastructure.

Open Referral: helping people find and access community resources
In this blog post, we explore how Open Referral is using open data to connect people with services that can help them, the infrastructure needed to support that data, and the importance of balancing interoperability and flexibility in data standards.

OpenActive: using open data to help people get moving
In this blog post, we explore why data about physical activities matters, the tools and infrastructure needed to support that data, and how data strategy can help ensure that data is useful, usable and in use.

Announcing Flatterer: converting structured data into tabular data
In this blog post, we introduce Flatterer — a new tool that helps convert JSON into tabular data.
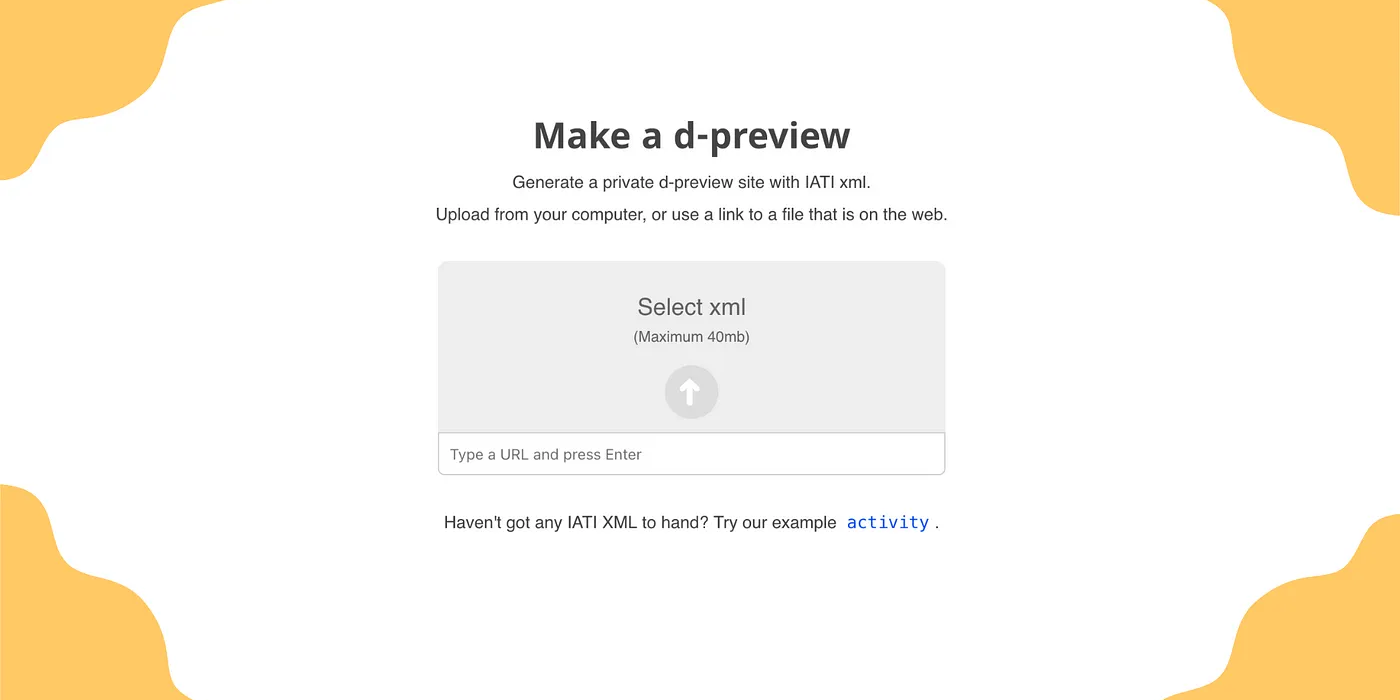
Previewing data before publication: what we’ve learned from 1 year of d-preview
At Open Data Services, we help organisations publish high quality, open and standardised data. One thing we’ve learned along the way is the importance of helping people to visualise that data clearly and effectively at every stage of the publishing process.

Why do open organisational identifiers matter?
At Open Data Services we build and support multiple data standards working across complex policy areas. There’s one feature all of the data standards we work on have in common — references to organisations.

UK government commits to publishing data using the Beneficial Ownership Data Standard
The UK government has announced its commitment to collect, use, exchange and publish beneficial ownership information using the Beneficial Ownership Data Standard (BODS) after approval by the Open Standards Board.

How policy informs technology, and technology informs policy: building a data standard for beneficial ownership transparency
In this blog post, we reflect on our work on the Beneficial Ownership Data Standard, and share what we’ve learned about how technology and policy can work together.

From freelancers to co-operators: the power of co-ops and working together
Last week, we joined forces with Co-operatives UK for Freelancers unite! The power of co-ops and joint working. Watch the webinar to hear Steven Flower discuss scaling our co-operative from 4 to 23 — and what we’ve learned along the way.
Strengthening Social Care: using open data to make social care and support accountable
How do you create a shared digital infrastructure for making care open, accountable and transparent? In this blog post we explore the state of data about social care in the UK, how we’re working with Equal Care to improve it, and what needs to be done next.
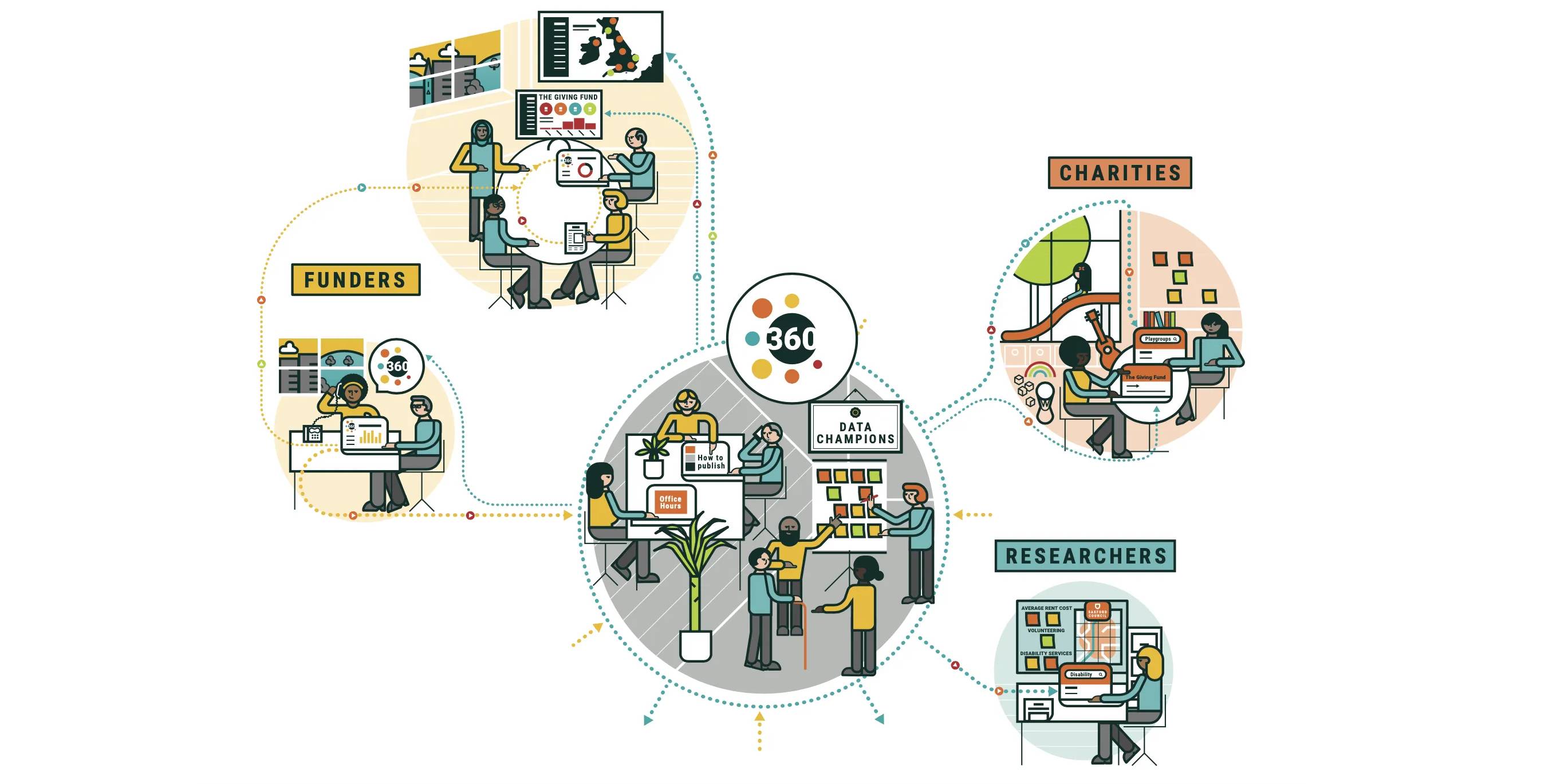
How to publish useful grantmaking data: what we’ve learned from 360Giving
Open Data Services helps people publish and use open data. We’ve been working with 360Giving since 2015 to help funders publish open and comparable information about their grants. In this blog, we share the benefits of publishing machine-readable data, the tools we’ve developed with 360Giving to support publishers to do so, and some common pitfalls organisations encounter when publishing.
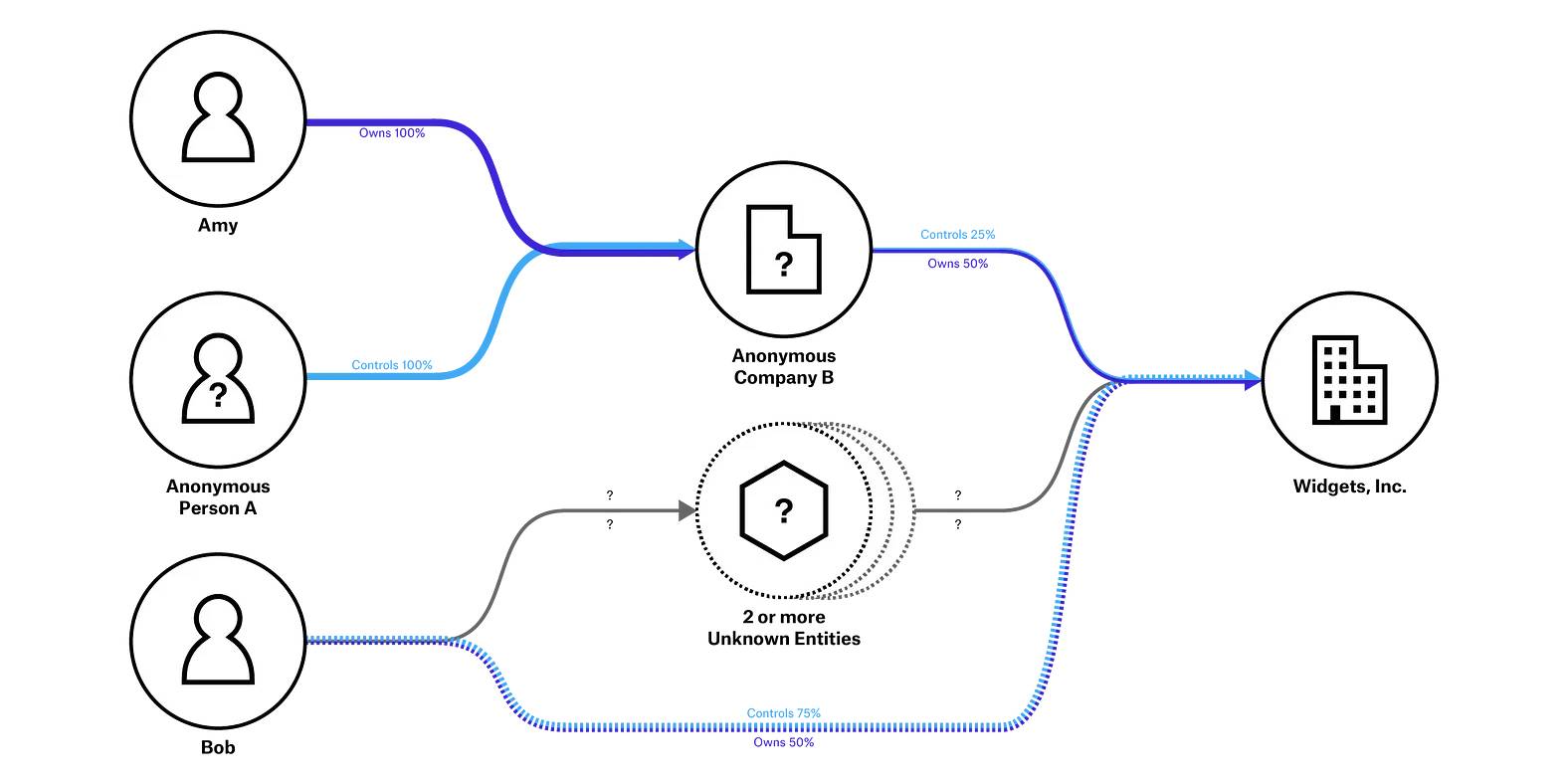
Armenia and Latvia publish BODS: building a data standard from scratch
Armenia and Latvia have become the first countries to publish data using the Beneficial Ownership Data Standard (BODS) to their company registers. Open Data Services have been supporting the Latvian and Armenian company registries to help them achieve this publication. It’s an exciting milestone on the path to beneficial ownership transparency — for the first time, governments are publishing data about who owns and controls companies (and other legal entities) in a way that supports better data.

Heads up: we’re hiring soon!
It’s Co-ops Fortnight,and this year Co-operatives UK are encouraging people to join a co-op. To mark the occasion, we’ve just made it easier to find out about opportunities to join our team.
Remote work is for life, not just for lockdown
As a team that has always operated remotely, we’ve been relatively insulated from the impact of changing working practices due to lockdown. In this blog post, we share how we made it through the past year and a half.

Strengthening Social Care with open data: making care and support accountable to the people who matter most
We’re delighted to announce our work with Equal Care Co-op on the Health Foundation’s Strengthening Social Care Analytics programme. Our project aims to create a shared digital infrastructure for open, accountable and transparent social care.
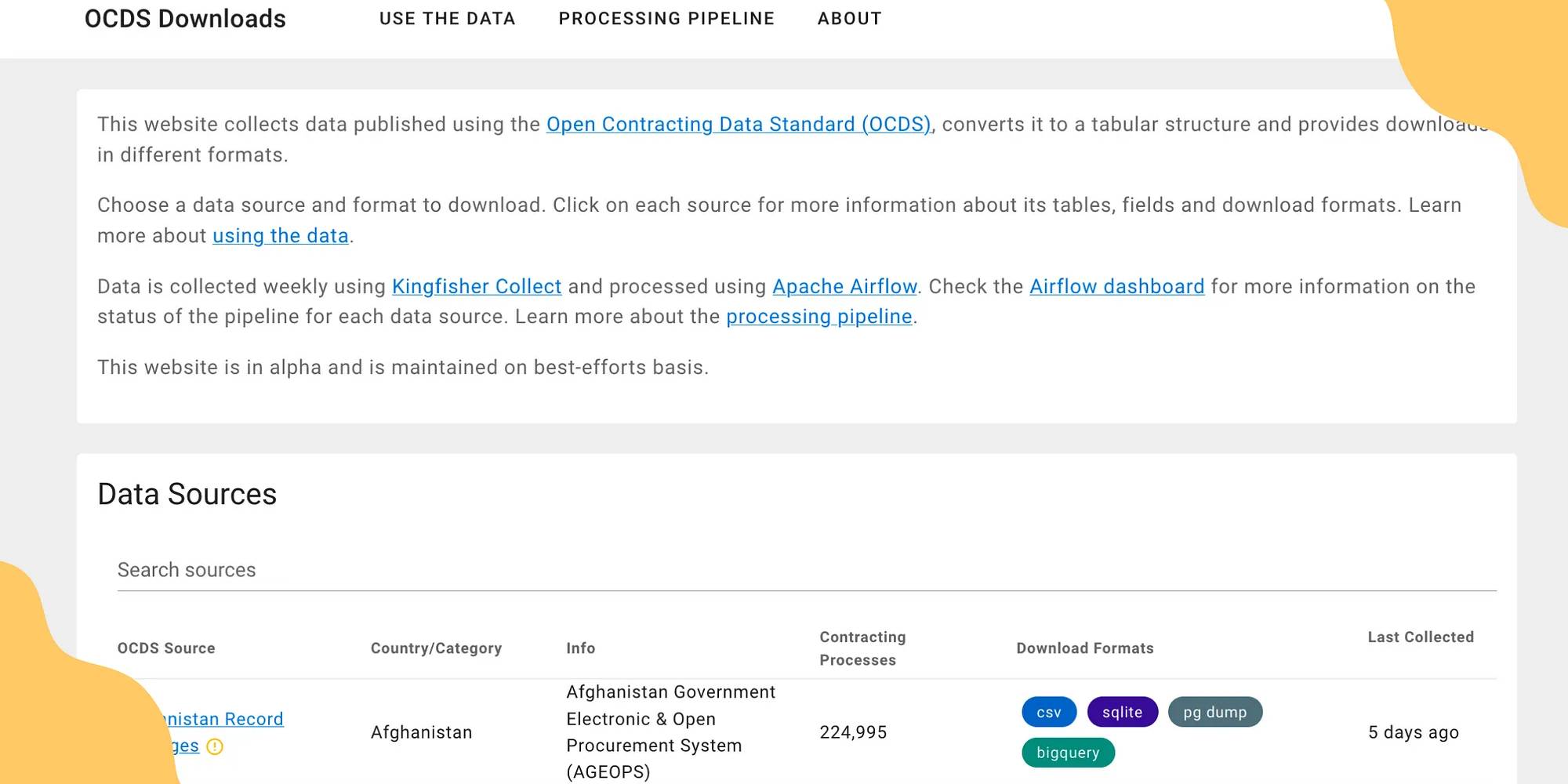
Announcing OCDS Downloads: making it easier to work with data published using the Open Contracting Data Standard
We’re pleased to announce the initial version of OCDS Downloads — a new website that provides access to data published using the Open Contracting Data Standard in analyst-friendly tabular formats.

Introducing Standards Lab: an experimental environment for data standards
Over the last few months, Open Data Services developers and researchers have been beavering away developing Standards Lab. Standards Lab is a new tool that builds on CoVE to provide an experimental environment for developing new or existing open data standards.
The project is funded by the Open Data Institute as part of their Tools Development for Data Institutions and Data Access Initiatives project.

What’s CoVE got to do with it?
At some point in your interactions with our co-operative, you might have heard us talking about CoVE.
But what exactly is CoVE, and how do we use it? In short, if CoVE didn’t exist our work would be much more difficult. CoVE (which stands for Convert, Validate and Explore) is a utility that sits at the heart of our co-operative. It started as a way to transform data between JSON and CSV files — but has since grown to include many different features that helps us to help others to publish and use open data. It’s also open source, so anyone is free to build on it.

Building prioritisation processes for our co-operative work
Prioritising workloads operates differently in a non-hierarchical organisation. When there’s no chain of command, all prioritisation comes out of shared agreement. We recently blogged about how we’re developing decision making mechanisms we use to function more equitably. As our mechanisms improved, we realised that we were applying them to decisions small and large, urgent and inconsequential.
Given that decisions generally take more time, we thought that we should start to treat them more like the internal projects we carry out to improve our co-operative. In short — what makes something a priority, and how can we judge that as a co-operative?
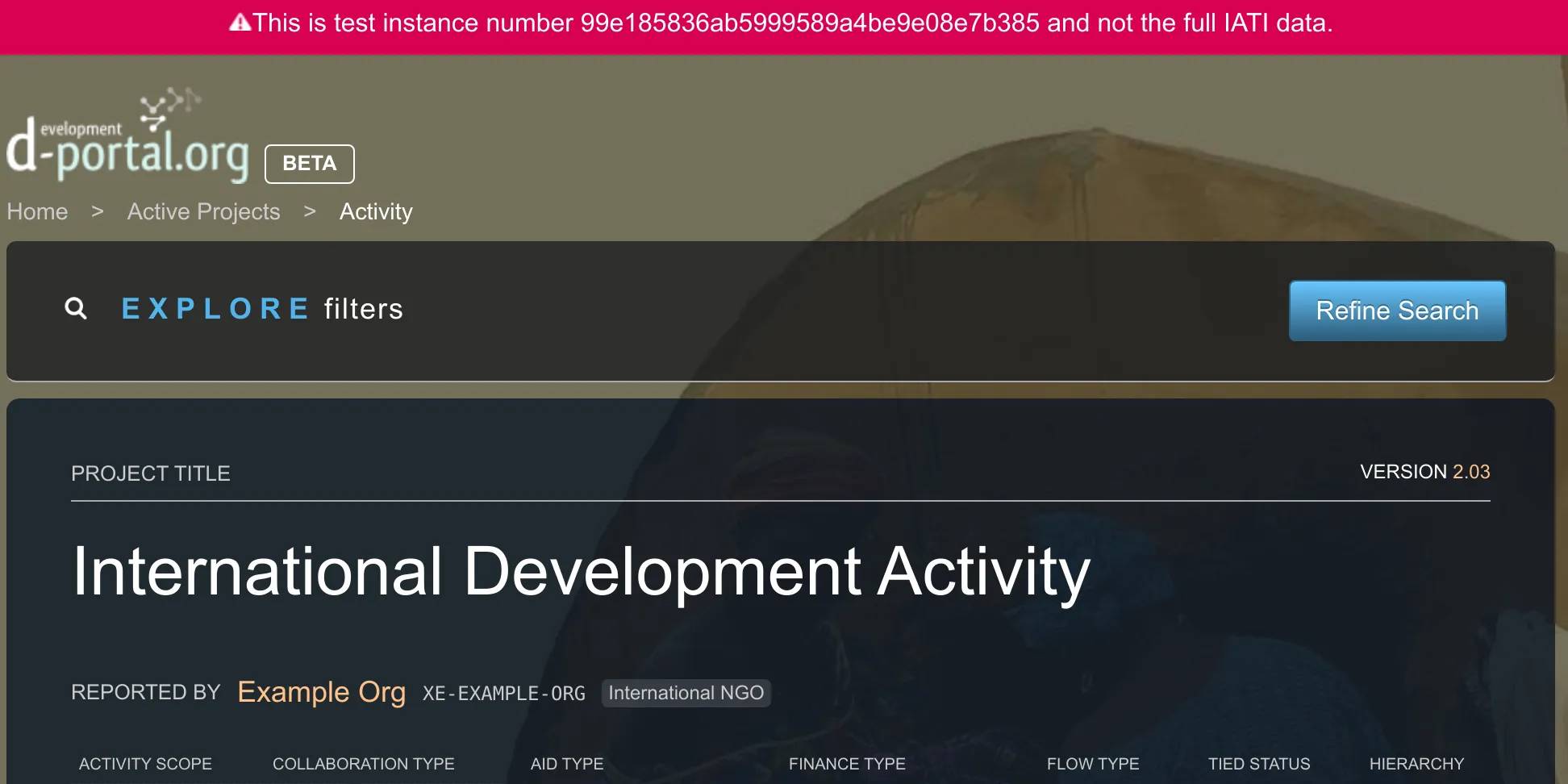
Announcing d-preview: helping organisations check their IATI data before publishing
Many years of working with organisations to produce open data has consistently reaffirmed one thing: it’s important for people to preview their data before publishing it. Preview both provides a way for people to check that they’ve put their data together correctly, and provides an immediate dose of motivation — it’s likely that they’ve never seen that data presented visually before.
We’re pleased to announce d-preview. This is a service open to anyone — either through the upload user interface or programmatically.
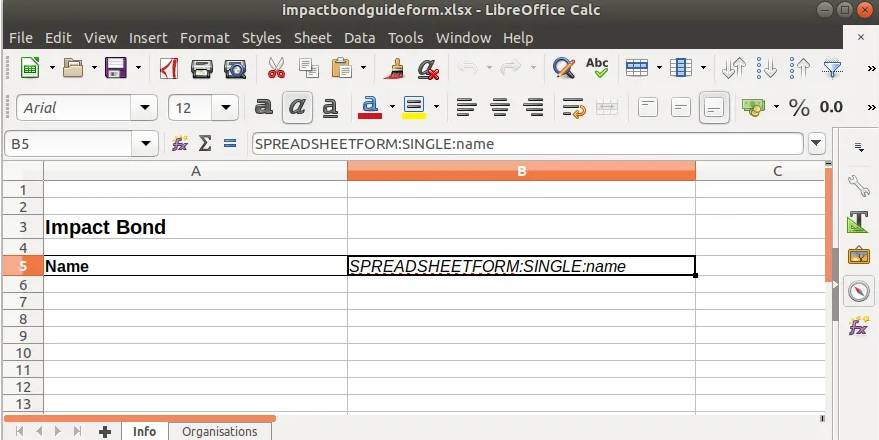
Introducing our new Python library: Spreadsheet Forms
Have you ever been in a situation where you wanted to collect some data from people? Was the best thing to do to send them a spreadsheet, ask them to fill it in and then send it back? We’ve seen situations like this and we wanted to make a library to make this easier to work with.
And thus we introduce our new Python library — Spreadsheet Forms.

Connecting the dots between beneficial ownership and procurement data: improving processes and identifying risk
This is the first in a series of blog posts exploring how beneficial ownership and procurement transparency can support each other. We explore how the different requirements of procurement and beneficial ownership transparency result in very different systems and data structures, and how contracting processes can be strengthened by incorporating beneficial ownership data in the near future.

A beginners guide to identifiers: linking beneficial ownership and open contracting data
Joining up datasets can be tricky, even when you’re working with standardised data. One challenge that we often face is being sure something in one dataset is the same as (or different to) something in another. In other words, how can we unambiguously identify something that is being represented? In this blog post, we’ll explore what makes a good identifier, why we need to use them, and how they enable us to easily link datasets, using sample data from the Open Contracting Data Standard and Beneficial Ownership Data Standard as an example.

Creating a data standard for infrastructure transparency: putting it to use
We’ve been working with CoST — The Infrastructure Transparency Initiative and the Open Contracting Partnership to develop the Open Contracting for Infrastructure Data Standard (OC4IDS). It’s an open standard for the publication of joined-up data about infrastructure projects and contracts.
We’ve recently released an update to OC4IDS, so to celebrate we’re publishing a series of blogs. In this part, we’re reflecting on the challenges and opportunities for infrastructure projecttransparency based on our experience supporting the implementation of OC4IDS.

Building open decision making mechanisms for our co-operative
We try to do things in an equitable, non-hierarchical way in our co-operative. Making our decisions more explicit by documenting and communicating the mechanisms we use is one small part of this process. In the early days, we tended to rely on consensus alone to make decisions. As we’ve scaled, we’ve defined what we mean by consensus, and added new ways to make decisions that allow us to take action quickly, while ensuring everyone has a chance to put forward their questions or concerns.

Technical case studies: What can we learn from the choices made by Open Contracting Data Standard implementers?
Over 30 different government agencies have now implemented the Open Contracting Data Standard. Most implementations have some things in common, but the context and constraints for each differ. As such, the technical choices made by each implementer also vary. Our technical case studies report documents 5 different OCDS implementations. The aim of the report is to provide insights into the technical choices made by implementers. The report also seeks to highlight the impact of these choices on data users.

Creating a data standard for infrastructure transparency: building it
We’ve been working with CoST — The Infrastructure Transparency Initiative and the Open Contracting Partnership to develop the Open Contracting for Infrastructure Data Standard (OC4IDS). It’s an open standard for the publication of joined-up data about infrastructure projects and contracts.
In this blog post, we look at how we built OC4IDS — how we structured the standard, how we thought more broadly about re-use, and the tools and resources we’ve built to support implementation.

Creating a data standard for infrastructure transparency: laying the foundations
We’ve been working with CoST — The Infrastructure Transparency Initiative and the Open Contracting Partnership to develop the Open Contracting for Infrastructure Data Standard (OC4IDS) – an open standard for publishing joined-up data about infrastructure projects and contracts.

What we’ve learnt running bilingual remote workshops
Although our co-operative has always worked remotely, a lot of our work has involved international travel. This changed in 2020, as workshops that we previously would have delivered in person are now being conducted online. We’ve found that there are some additional considerations to take into account when running sessions remotely and bilingually.
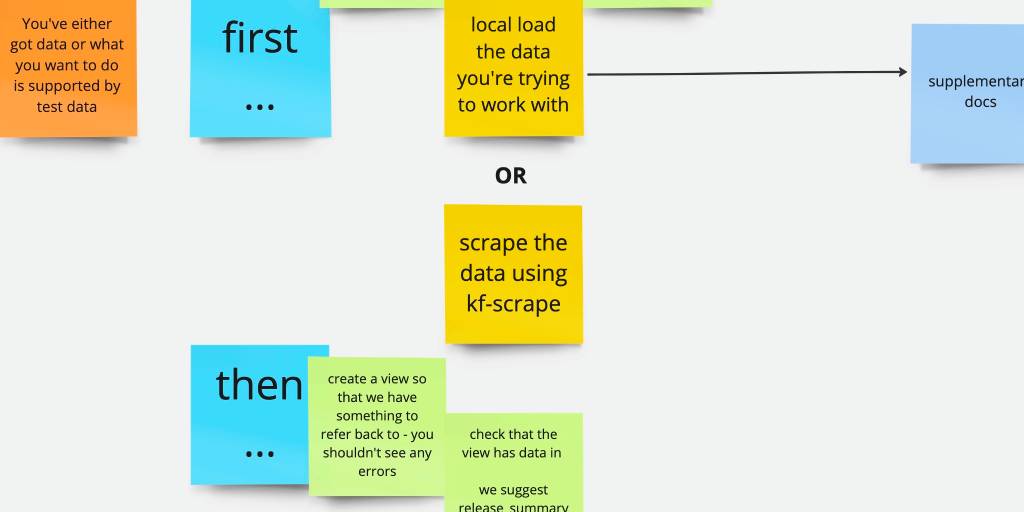
First, then, finally: writing useful documentation
When you’re writing documentation it’s really easy to gloss over important details, or not really think about what it would be like for someone else to follow the instructions. At Open Data Services, we use the First, Then, Finally method to think through the process, stay focussed and write useful docs.

Opening up political influence: announcing declared.
We’ve been working with OpenDemocracy to help build declared. — a prototype search engine and data explorer that collects declarations of interests, gifts, employment and more from elected members of bodies around the UK. It’s a proof of concept that shows what we could do if politicians were required to declare their interests as open, standardised data.
The project was funded by the Future News Pilot Fund by the Department for Digital, Culture, Media and Sport via Nesta.

To be truly open, you need to standardise
So, you publish some open data? That’s great. If you’re getting the basics right, people can get your data easily, open it with free software, know what they can and can’t do with it, understand its structure, uniquely identify things within it, and connect it to other data sets. But how do they find out what it means?

Form Follows Function: Collecting Beneficial Ownership Data
To collect good data, you need to design good forms.
A well-designed form helps well-meaning people to provide good data, and makes it difficult for bad actors to provide bad data. We’ve worked with Open Ownership to improve beneficial ownership disclosure forms.

360Giving’s Datastore: a coming-of-age story for open data pipelines
We’ve been working with 360Giving to help funders publish open data about their grants, and empower people to use this data to improve charitable giving.
Sharing code to strengthen the open data ecosystem
A principle of Open Data Services is that we routinely reuse code across different projects and publish our work on Github. We think this makes sense — it means we can spend more time improving and tailoring our systems for a specific project, rather than reinventing the wheel.
How to run a useful community data project
Recently we have seen several projects attempting to map community data to help people in these coronavirus times. We can understand why. People need good information more than ever, and they need information on a range of services and topics they weren’t looking up before.

Open Data Services Turns Five: what we’ve learned from one big user testing story
In March 2015, Open Data Services Co-operative was founded by four freelancers who wanted to combine working in open data with an equitable business model. As we enter our fifth year, we’re now eighteen members providing key infrastructure that allows open data to be useful, usable and in use.

Happy Open Data Day and International Womens Day: making careers in open data work for women
This weekend marks both Open Data Day and International Women’s Day. Because we strive to make careers in open data work for people, we wanted to use this weekend to highlight the women in our team, their experiences in tech and their advice for starting out in open data.

Towards a toolkit for policy focussed open data standards
Open data standards are at the heart of our work. But not just any technical standards: standards that bridge between policy and technology worlds.
Over the years we’ve picked up lots of learning and insights on approaches to support standard development and adoption, but we’ve rarely had chance to capture and write up that learning. Which is why we were delighted to take part last year in the Open Data Institute’s Open Standards for Data project.

Open Data Standards for Social Impact
At the end of October we brought together a number of projects making use of open data standards for policy impact. Together, we explored some of the elements that make for effective open standards. This is the first post in a series capturing some of the learning.
subscribe via RSS